Modèle de données Artsdata v1.0
Un modèle de données pour représenter les événements, les œuvres, les lieux, les personnes et les organismes dans arts de la scène.
Le modèle de données (ontologie) d’Artsdata est un sous-ensemble de Schema.org et d’autres ontologies avec quelques vocabulaires contrôlés additionnels. Le modèle d’Artsdata.ca est représenté formellement avec le language SHACL ici.
Les classes et propriétés utilisées dans Artsdata s’apparentent au modèle de Données structurées d’événement de Google. En particulier, les propriétés obligatoires pour les événements dans la documentation de Google sont aussi des propriétés obligatoires dans le modèle de données Artsdata. La différence principale est qu’Artsdata s’appuie sur les identifiants pérennes pour lier les données d’Artsdata avec d’autres bases de connaissances ouvertes telles que Wikidata.
Voici les Classes utilisées dans Artsdata.
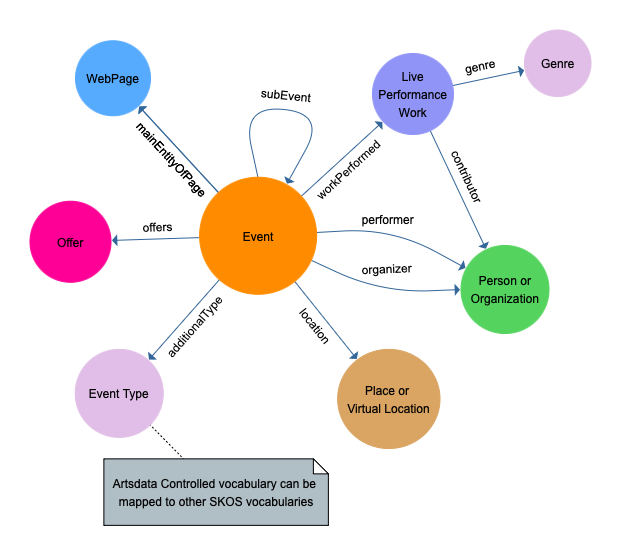
Classes
- EventAttendanceModeEnumeration
- EventStatusType
- Event
- LivePerformanceWork
- Offer
- Organization
- Person
- Place
- PostalAddress
- VirtualLocation
- WebPage
Identifiants pérennes
Artsdata génère ses propres identifiants globaux uniques et pérennes (IRI aussi appelée URI) pour les entités des classes événements, spectacles, lieux, personnes et organisations, ainsi que pour les concepts de vocabulaires contrôlés. Ces URIs peuvent être utilisés en dehors d’Artsdata.
En plus de l’identifiant Artsdata, le graphe de connaissances Artsdata s’appuie sur d’autres identifiants pérennes, comme l’identifiant Wikidata, l’ISNI et les identifiants locaux, afin de reconnaître, de réconcilier et lier les entités nommées.
Lignes directrices à propos des identifiants pérennes
Vocabulaires contrôlés
Gabarits de données structurées
Rapports de validation SHACL
Les formes SHACL sont utilisées pour valider les données avant l’importation.
Ontologies et inférences
Artsdata.ca utilise un ensemble de bases d’implications RDFS et OWL afin de permettre une inférence simple, appelé OWL-Horst (optimized).
La principale ontologie utilisée dans Artsdata.ca est Schema.org. Artsdata.ca importe le schéma de base Schema.org et le schéma Schema.org en attente (pour inclure schema:EventSeries qui est une classe en attente). Plusieurs autres ontologies sont utilisées, notamment DBpedia, DCAT, DATAID, PROV, SHACL, VANN, VoID, SKOS et Wikidata.
Artsdata.ca a un grand nombre de mises en correspondance de classes et de propriétés avec Schema.org, Wikidata.org, DBpedia.org, LRMoo, CIDOC-CRM, FRBRoo, AAT, Nomenclature, DCMI, FOAF et DOLCE+DnS Ultralite (Ontology Design Patterns). Les correspondances sont établies en utilisant owl:equivalentClass, owl:equivalentProperty, skos:exactMatch et skos:closeMatch. Certains mappages sont préconstruits à partir d’ontologies externes; d’autres sont définis dans Artsdata.
Ontologies chargées dans Artsdata
Provenance
En cours de traduction…
Architecture des flux de données
En principe, n’importe qui peut ajouter des données à Artsdata.ca pourvu que certaines exigences en matière de données soient respectées. Voici un diagramme sur la façon dont les données entrent et sortent d’Artsdata.ca.
Données ouvertes et liées, mise en cache
Artsdata.ca charge les données ouvertes et liées de Wikidata et DBpedia afin de les mettre en cache pour des raisons de performances. Les triplets sont obtenus en utilisant la négociation de contenu (au lieu de vidages de données) et sont mis en cache sans modification dans leurs graphes nommés respectifs.
Remarque: il existe une exception notable, la propriété Wikidata P31 (instance de) est transformée en rdf:type. Ce même résultat aurait pu être obtenu en utilisant owl:equivalentProperty mais il n’a pas été sélectionné pour des raisons de performances.
Conventions de nommage
Conventions sur la façon de nommer les choses en cas de doute.